Home » Posts tagged 'data-driven market'
Tag Archives: data-driven market
ChatGPT vs. Bard in search engines: good to have a theory
[Slight update below, 18 August 2023]*
On November 30, 2022, Open AI released its chatbot ChatGPT [1]. Many users were immediately thrilled because of the bot’s unprecedented quality, some firms saw strategic opportunities: on January 23, 2023, Microsoft announced a deepening of their partnership with OpenAI, ChatGPT’s developer [2] and confirmed a U$10bn investment soon after [3].
While the chatbot has many (potential) applications, an obvious one is to use it in search engines, in order to improve the quality of search results. Alphabet, the owner of the leading search engine, Google, had the same thought: they reacted on February 6 by announcing Bard, “a conversational AI similar to ChatGPT” [4]. Microsoft reacted immediately and confirmed on February 7 that they are actually planning to add ChatGPT’s functionality to their own search engine, Bing [5].
So much for the empirics until today. Naturally, many companies, investors, decision makers in politics and society, and a zillion users are asking themselves what will happen now [6]. The scene looks like a clash of titans. But is it really?
While I cannot comment on the many other battlefields the two chatbots will compete on, for the (economically and societally highly relevant) search engine market (and related “data-driven markets”) we have a scientific theory, at least. The idea and mechanism of “Competing with Big Data” (joint work with Christoph Schottmueller) is described in earlier blog posts and was published as an academic journal article in 2021.
The theory of data-driven markets
The theory studies a market with two (main) service providers. If on this market (i) the interaction between users and a provider works via computers, which enables a provider to save many characteristics (e.g. IP address) and decisions of users (e.g. where to click) in search log files and (ii) if these user information about users’ preferences and characteristics are a valuable input into the provider’s innovation process (e.g. because they know what extra product features users really want), then we call such a market “data-driven.” In economic terms: the marginal cost of innovation must be decreasing in the amount of user-generated data (which is a function of demand).
If a market is data-driven, this has tremendous consequences. Look at the left panel of the following figure, which is taken from the academic article. It displays a numerical simulation of (equilibrium) investment decisions of both firms over time (red dots for firm 1 and black stars for firm 2) and the resulting market shares (blue curve: the vertical value 0.0 means 50% market share of each firm, 1.0 means firm 1 has 100% market share and firm 2 has 0%).
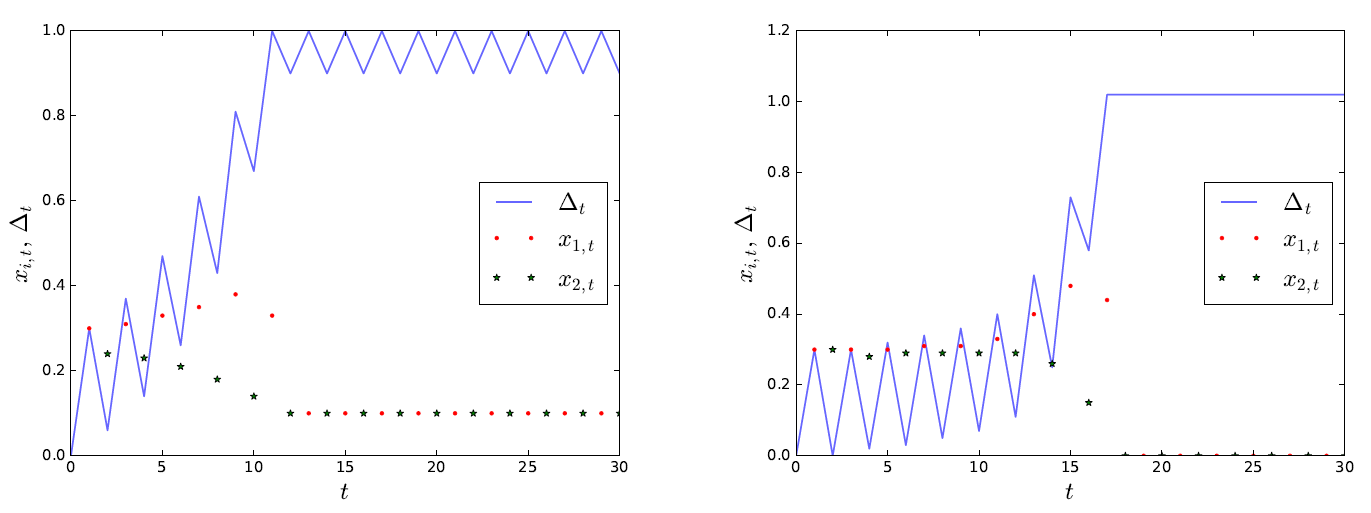
At the start of the simulation, we assumed 50:50 market shares. Firm 1 only had one advantage because it could invest in innovation first, which increases its product’s quality and, hence, market share. Only in period 2, firm 2 could innovate itself (and so forth, i.e. firm 1 invests in odd periods, firm 2 in even periods; this alternating order has game-theoretic reasons. For details, see the paper).
What the figure shows is that, for several periods, both firms invest heavily in innovation: they compete for the market. However, due to the steadily decreasing market share of firm 2 (the blue curve on average goes up), its marginal innovation cost increases. Consequently, it invests less and less in innovation (the black stars decrease). By contrast, firm 1 benefits from its first-mover advantage and, due to more data and lower marginal cost of innovation than its competitor, can innovate heavily (red dots increase). Crucially, this process of intense innovation of firm 1 stops when it has reached a very high market share (blue curve is approaching 1.0). Then, firm 2 has given up (red stars remain at low level). Firm 1 is dominating the market, constantly renewing its stream of user-generated data, and enjoying monopoly profits. Gladly, it does not even need to spend large sums on innovation, anymore (also red dots sink and then remain at low level).
The right panel of the figure captures a situation where profits in the future are even more important. Here, firm 1 is incentivized to innovate until firm 2 is literally kicked out of the market (has 0% market share) and does not innovate at all. As a best response, firm 1 also does not innovate at all (red dots and black stars remain at zero). Both figures show that, after the initial phase of competing for the market, firm 1 virtually monopolizes the market: economists say, the market has tipped.
Key intuition
Before we go back to the case of ChatGPT vs. Bard, it is crucial to understand why firm 2 does not innovate once the market has tipped. Assume firm 2 has a great idea for a better product. Its problem is its very low market share, which implies that its algorithm has access to relatively little user information. Consequently, its marginal cost of innovation are high. If it does roll out its great idea, for which it will need deep financial pockets, it can convince some users and gain a bit of market share (see the left panel after market tipping/period t=12, where the blue curve decreases a bit for one period). Firm 2’s problem is that firm 1 also learns about the great idea and will try to copy it (=invest in innovation) — however at much lower cost of innovation because it has such an advantage in valuable user-generated data. Consequently, after a brief fight firm 2 will be back at its very low market share — but still have to pay back the debt for the attempted innovation leap. Therefore, in equilibrium (i.e., in a stable situation) firm 2 (or any other firm considering market entry) is deterred from attempting to innovate heavily. This explains low degrees of innovation in a tipped data-driven market.
Back to the case!
One interpretation of the developments around ChatGPT and Bard sketched above is that Google has just enjoyed its super-dominant position on the search engine market (with a global market share of 92.9% over the past 12 months [7]) for a very long time. Alphabet may have innovated a lot elsewhere but improvements in Google’s organic search result quality over the past decade, or so, have been relatively modest, while its profits and market capitalisation soared.
Evidence: In an experiment with a small search engine, we recently showed that, for popular search queries where the algorithms of all search engines have sufficient user-generated data, Google’s quality is not assessed better than Bing’s or even than that of a small search engine (Cliqz) by human assessors (the assessors did not know which engine the search results came from). Only for rare queries, where Google has so much more user-generated data to train its algorithm what users are looking for, the small search engine could not compete anymore. Unfortunately for the small search engine, 74% of the traffic in our data consisted of rare queries, which may explain why Cliqz went out of business shortly after our experiment in April 2020.
That paper also showed that the search engine market is data-driven and that, hence, the theory of data-driven markets explained above is applicable.
Bringing the theory to the case
Google’s relative long-term idleness in search engine innovation is no surprise in light of the theory. What is a surprise is that Microsoft, whose search engine Bing has underwhelming 3.03% market share globally [7], invests heavily in this data-driven market (in contrast to the “key intuition” above, explaining why firm 2 should not try to innovate). Apparently, Microsoft thinks that ChatGPTs technology is so revolutionary that it can overcome its huge disadvantage in accessing user-generated data. By reacting so quickly, Alphabet even testified to this interpretation to some extent.
These decisions, however, can also be interpreted from the perspective of the theory of data-driven markets, namely what economists call “off-equilibrium behavior”: the “key intuition” part above predicts no innovation attempts after market tipping. However, if firm 2 (here: Microsoft) invests heavily in innovation (U$10bn for ChatGPT), this forces firm 1 (Alphabet) to innovate as well (which is positive for users, by the way). Crucially, because firm 1 has much more data and, hence, much lower cost of innovation (recall that they were able to announce a competing chatbot only about two months after ChatGPT was launched), they can innovate relatively easily by copying the challenger’s innovation. This is expected to bring the market development back on the “equilibrium path” (see the figures above after market tipping): after one of the spikes where firm 2 invested in innovation, firm 1 regains its dominant position, whereas firm 2 returns to its low market share.
Even if ChatGPT has fantastic features, it is an algorithm that relies on access to data — and the experiment cited above has shown that not any data found on the internet but data about users’ characteristics and preferences, as captured in earlier searches, is key on this market. Even more, if “generative AI” within a search engine is set up to reply to all kinds of questions, including much richer language, this will only increase the share of rare queries in all search queries. Consequently, the dominant firm’s data advantage will be even more pronounced.
Summing up, the theory of data-driven markets does not suggest that Microsoft’s investment in OpenAI will be a game changer for the search engine industry. Now let us watch how life plays out!
——————————–
(NB: the best policy remedy for this situation seems to be mandatory data sharing, which is becoming regulatory reality in the EU soon [8]. Here is a proposal how to implement mandatory data sharing on data-driven markets.)
References
[1] https://en.wikipedia.org/wiki/ChatGPT
[2] https://blogs.microsoft.com/blog/2023/01/23/microsoftandopenaiextendpartnership/
[4] https://www.freethink.com/robots-ai/conversational-ai-google-bard
[5] https://www.wsj.com/articles/microsoft-adds-chatgpt-ai-technology-to-bing-search-engine-11675793525
